やったことのまとめ
- 同じ設定の
Prometheusを単純に複数台動かして冗長化した - 複数台の
Alertmanagerをメッシュとして動かして冗長化した
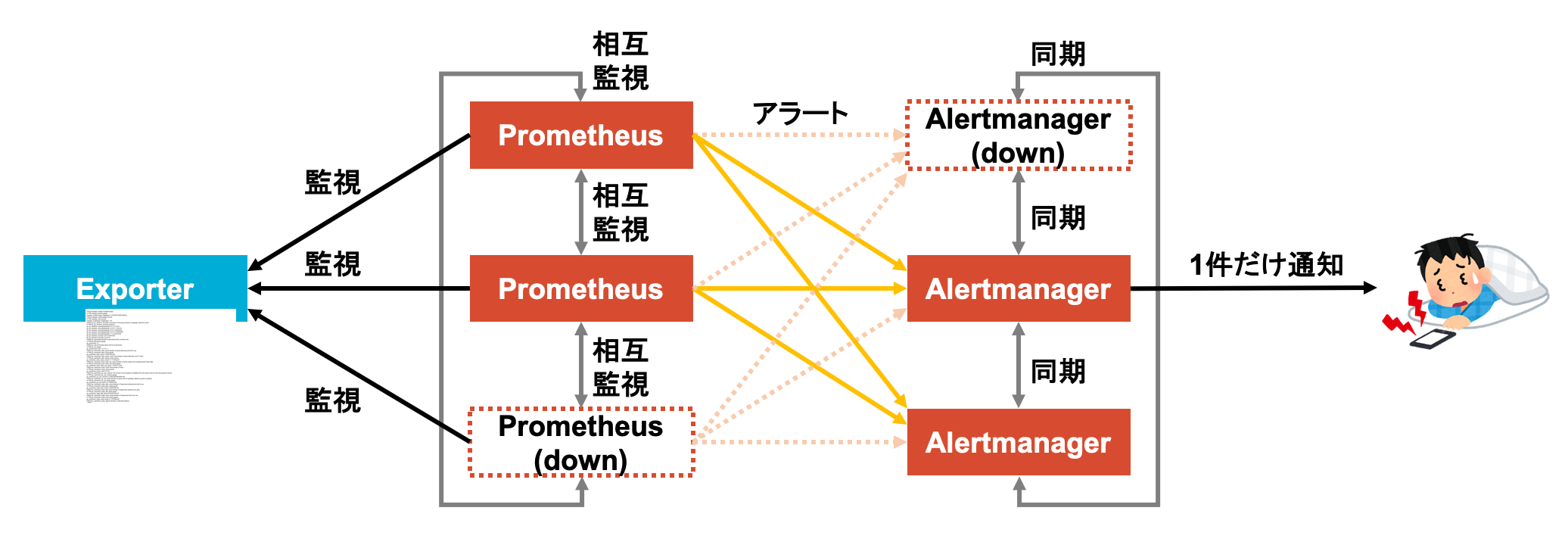
PrometheusとAlertmanagerでサービスを監視するのは良いんだけど, 1台ずつで運用してると監視コンポーネント自身がダウンしたときに監視できなくなってしまう.
だったら監視コンポーネント自体も冗長化すれば可用性を上げられるのでは?と思い試してみた.
Prometheusの時系列DBの冗長化はかなり難しいっぽいので今回はやらない.
Prometheusは単純に同じ設定のものを複数同時に動かし, Alertmanagerは複数台を同期してメッシュとして動かすのが良さそう.
つかうもの
- macOS Mojave 10.14
- Docker Desktop for Mac
- Version 3.1.0
- Docker Engine Version 20.10.2
- docker-compose version 1.27.4
- Prometheus (Docker)
- version 2.24.1
- Alertmanager (Docker)
- version 0.21.0
- Grafana (Docker)
- version 7.3.7
- nginx (Docker)
- version 1.18.0
やったこと
Prometheusを冗長化する
Prometheus公式のFAQによると可用性を高めるには
「同じ設定のものを複数台動かせ. 複数のPrometheusで同じアラートが発火した場合でもAlertmanager側で勝手に重複排除してくれる.(意訳)」1
とのこと. 単純で良い.
とりあえずPrometheusを3台立ててnginxで負荷分散(ラウンドロビン)する2ような構成をDocker Composeで作ってみた.
その他の設定は下記のとおり.
Prometheusx3prometheus.yml: 互いを監視するような設定を入れるrules.yml: 任意の設定
Alertmanageralertmanager.yml: 任意の設定
Grafanagrafana.ini: 任意の設定(リバースプロキシ対応)datasource.yaml:PrometheusをData Sourceとする設定
nginxdefault.conf:Prometheusのロードバランシング設定(やらなくても良い)
Prometheus, Alertmanager, Grafanaのリバースプロキシ設定は前回やったときとほぼ同じだけど, 今回の目的はPrometheusの冗長化なのでここらへんはやらなくても良い.
rules.yml, alertmanager.ymlの設定は有効なものなら何でも良いので前回と同じものを使う.
grafana.iniも一応前回と同じものを使うけど今回の目的はあくまでPrometheusの冗長化なのでデフォルト設定のままでも良い.
設定ファイルが準備できたらコンテナを立ち上げる.
# ディレクトリ構成
$ tree .
.
├── deployment
│ ├── alertmanager
│ │ └── alertmanager.yml
│ ├── grafana
│ │ ├── datasource.yaml
│ │ └── grafana.ini
│ ├── nginx
│ │ └── default.conf
│ └── prometheus
│ ├── prometheus.yml
│ └── rules.yml
└── docker-compose.yml
# コンテナ起動
$ docker-compose up -d --force-recreate
$ docker-compose ps
Name Command State Ports
---------------------------------------------------------------------------
alertmanager /bin/alertmanager --config ... Up 9093/tcp
grafana /run.sh Up 3000/tcp
nginx /docker-entrypoint.sh ngin ... Up 0.0.0.0:80->80/tcp
prometheus-01 /bin/prometheus --config.f ... Up 9090/tcp
prometheus-02 /bin/prometheus --config.f ... Up 9090/tcp
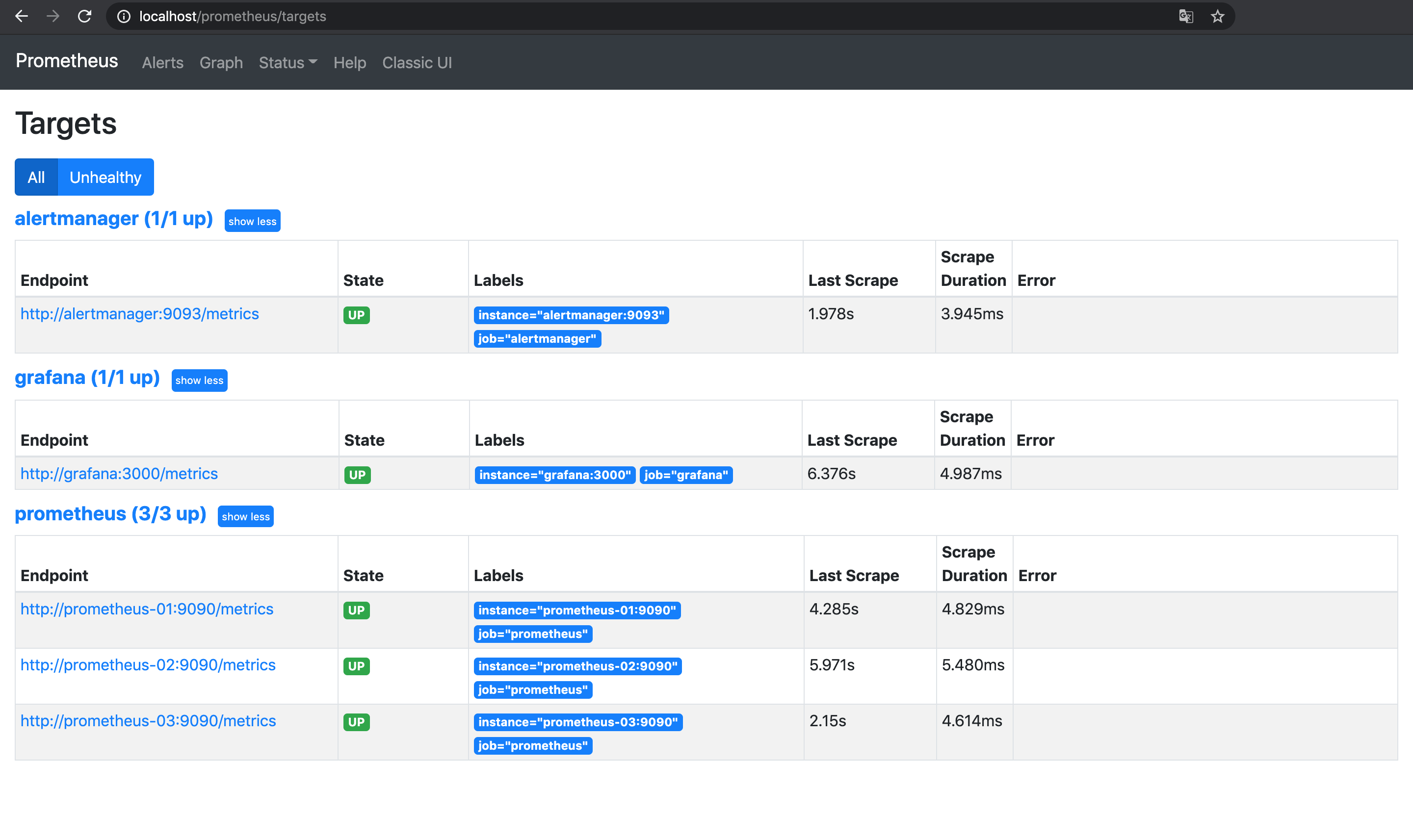
prometheus-03 /bin/prometheus --config.f ... Up 9090/tcpnginxで80番ポートが開けてあるので, http://localhost/prometheus/を開くとPrometheusが起動していることを確認できる.
画面上ではどのPrometheusコンテナがレスポンスを返しているのかわからないが, 実際にはnginxにより1台ずつ順番にリクエストを受け付けている(ラウンドロビン). はず.
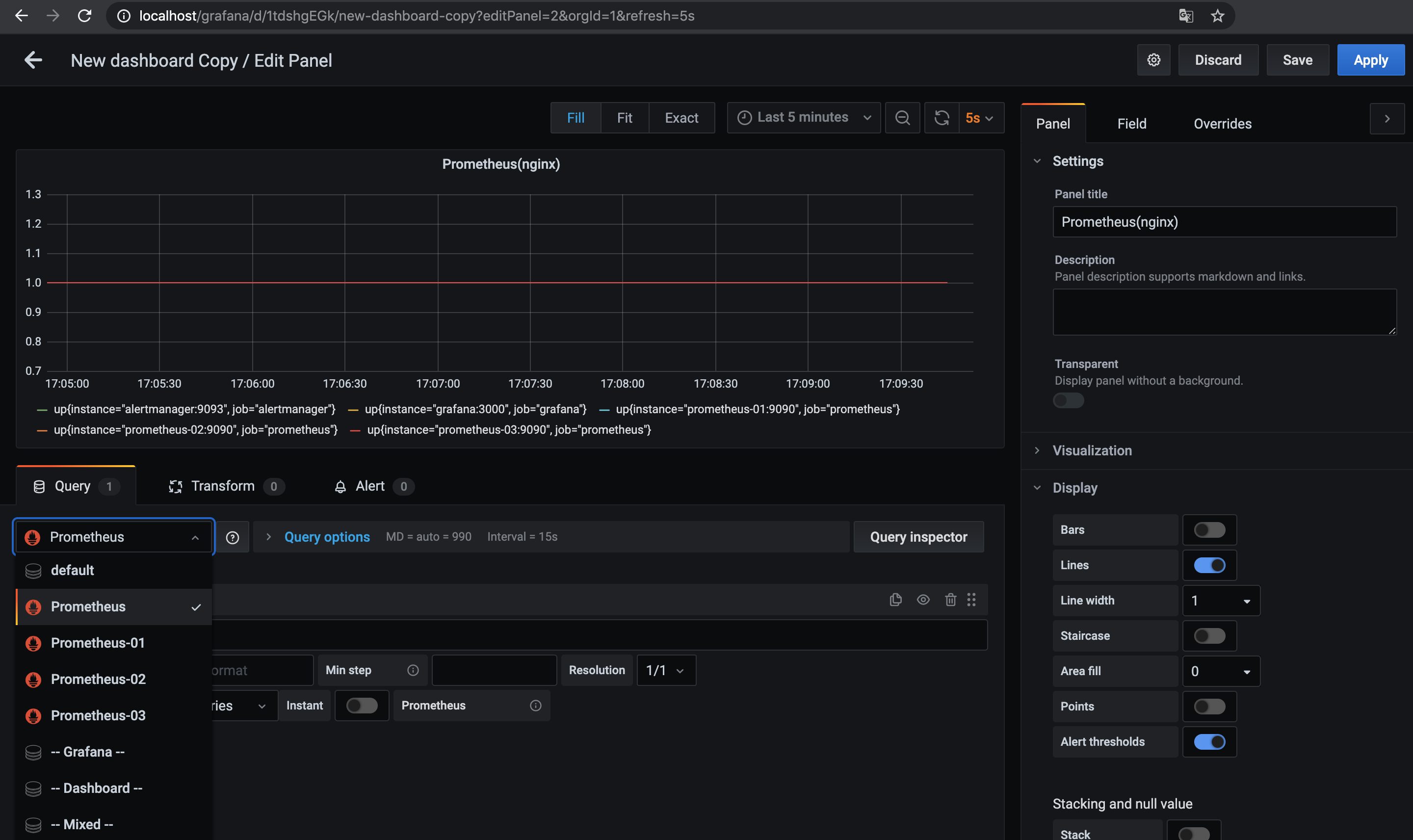
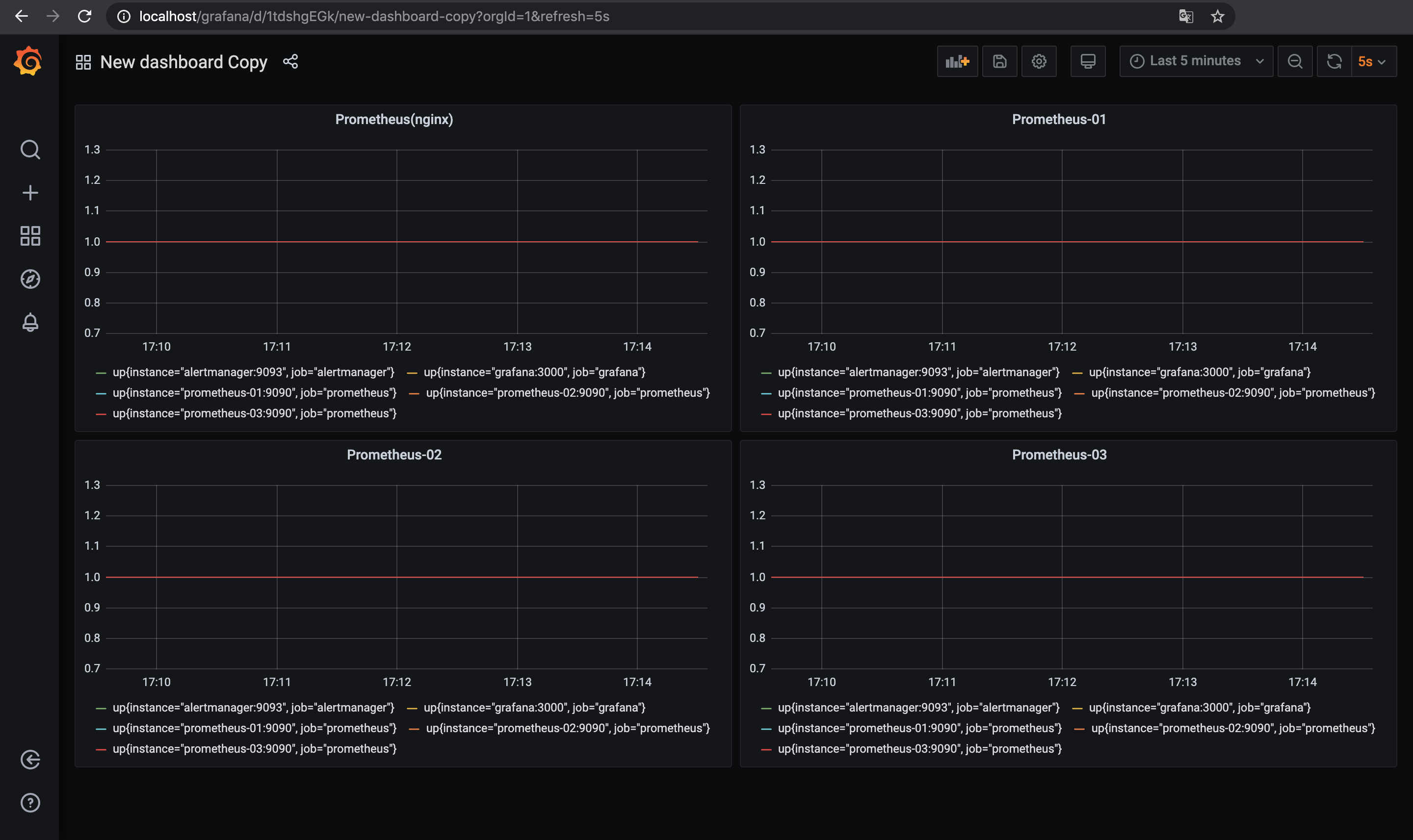
http://localhost/grafanaを開きGrafanaでダッシュボードを作成する.
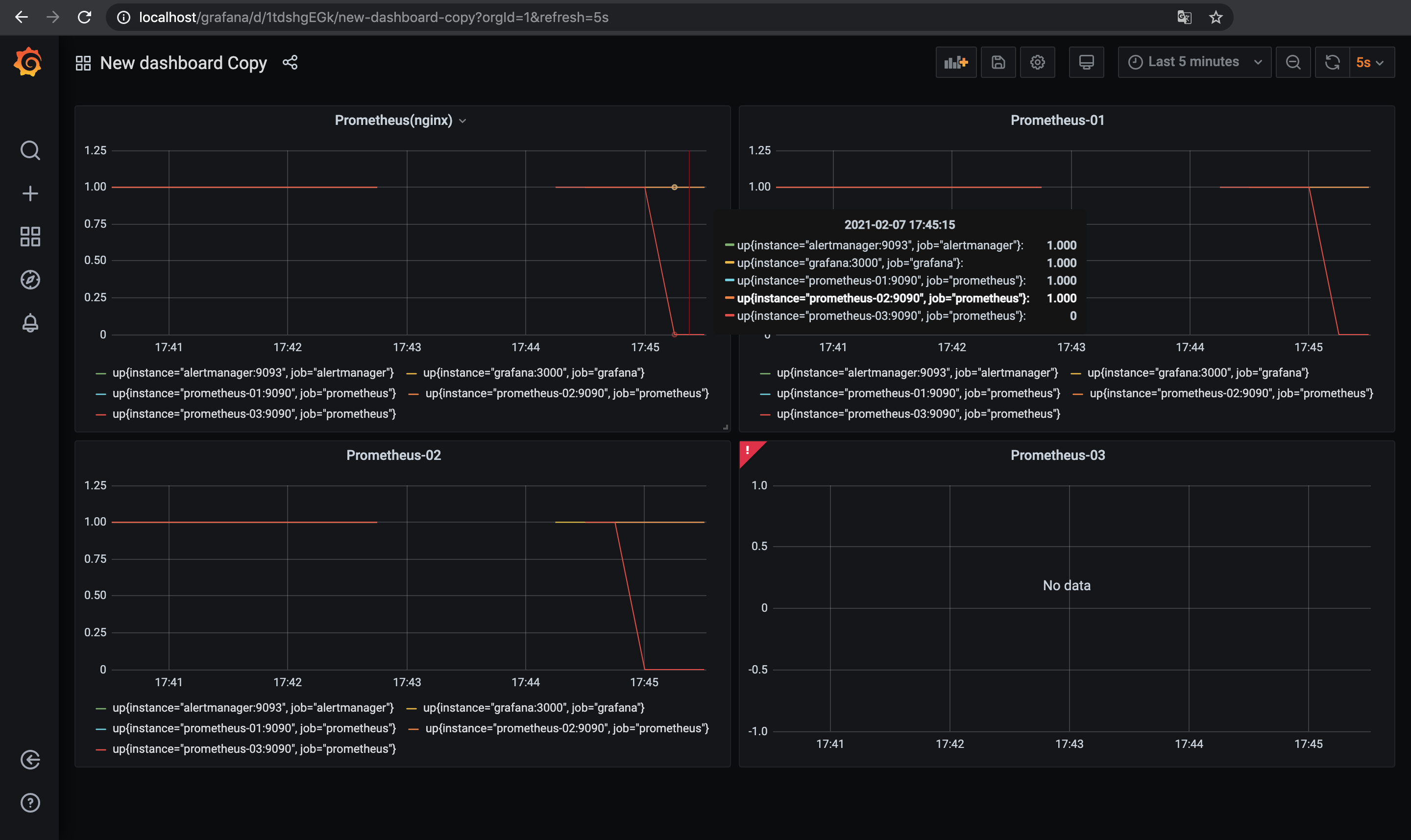
Data SourceとしてnginxのPrometheus用エンドポイントと念の為それぞれのPrometheus3台のエンドポイントを設定してあるのでそれぞれのData Sourceに対して同じメトリクス(up)のダッシュボードを作ってみる.
余談だけど今回はnginxロードバランサの下で複数台のPrometheusを動かしているので, GrafanaのData Sourceがnginx上のPrometheusエンドポイントを見ている場合はロードするたびに微妙にグラフ(メトリクス)が変わったりする.
この挙動が気持ち悪い場合はnginx上のエンドポイントじゃなくて個別のPrometheusをData Sourceにするほうが良いかもしれない(あとで気づいた).
この状態で3台あるPrometheusを一部落としてみる.
# Prometheusを2台落とす
$ docker-compose stop prometheus-01 prometheus-02
$ docker-compose ps
Name Command State Ports
----------------------------------------------------------------------------
alertmanager /bin/alertmanager --config ... Up 9093/tcp
grafana /run.sh Up 3000/tcp
nginx /docker-entrypoint.sh ngin ... Up 0.0.0.0:80->80/tcp
prometheus-01 /bin/prometheus --config.f ... Exit 0
prometheus-02 /bin/prometheus --config.f ... Exit 0
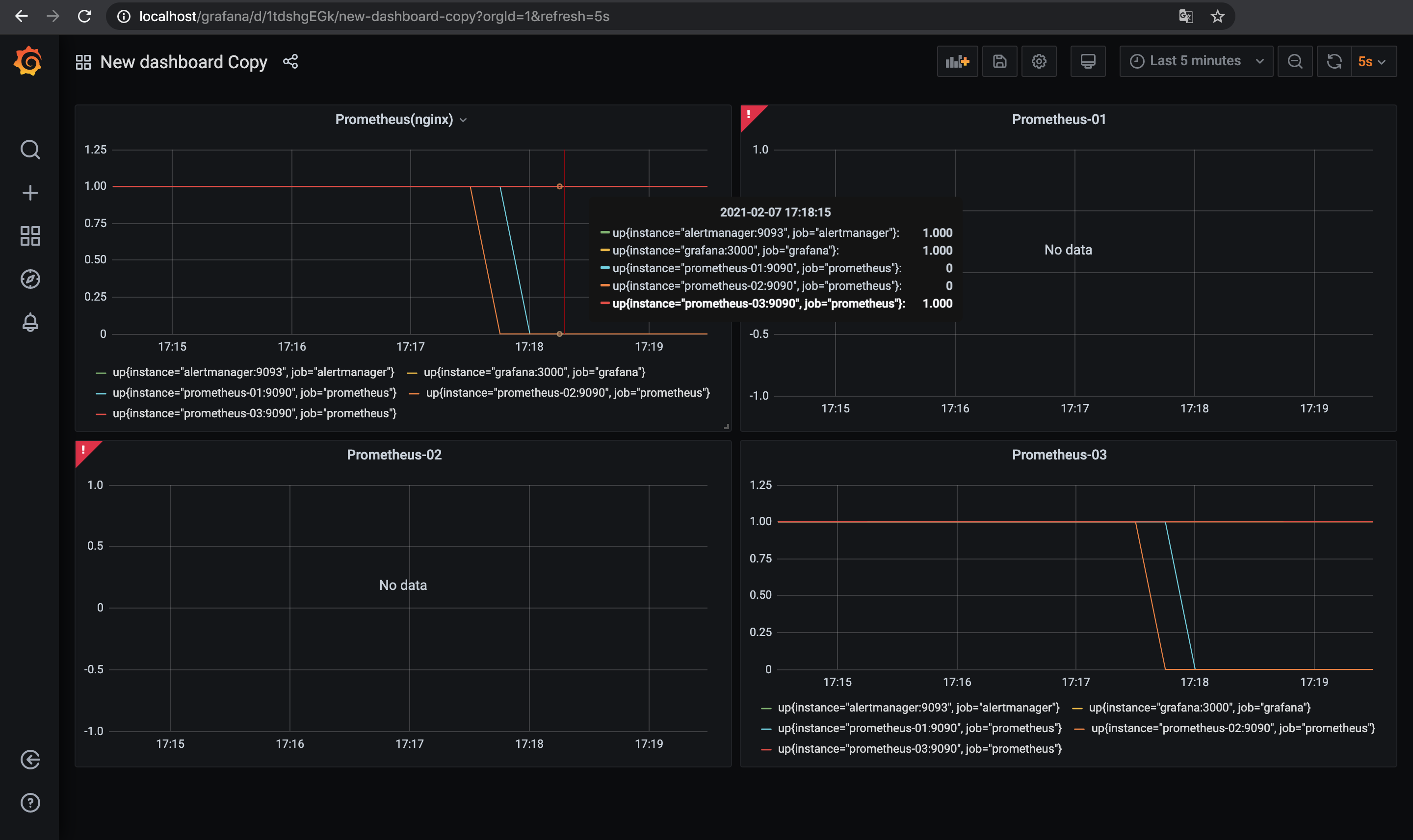
prometheus-03 /bin/prometheus --config.f ... Up 9090/tcp1台目と2台目のPrometheusを落としたので, 3台目のPrometheusでInstanceDownのアラートが発火する.
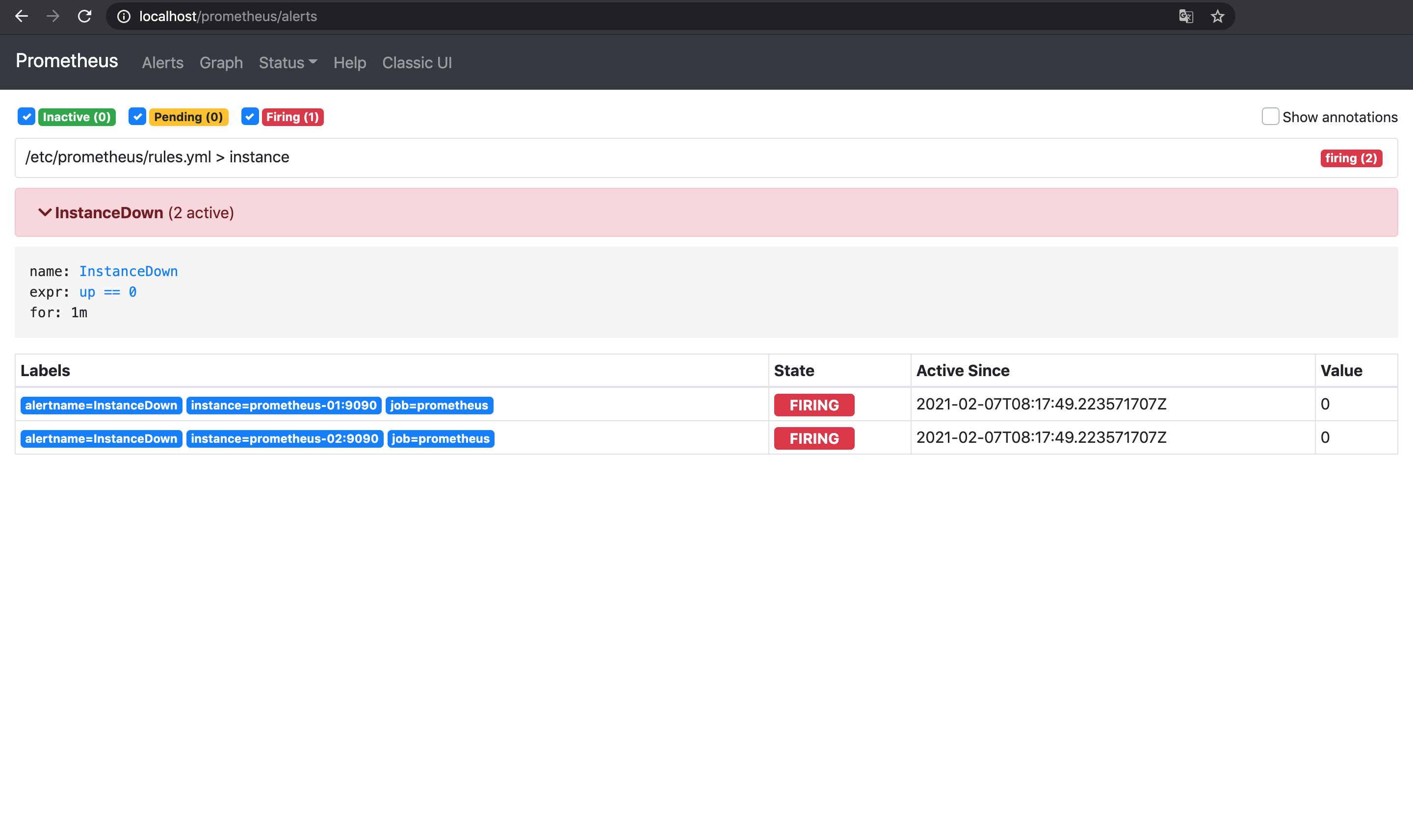
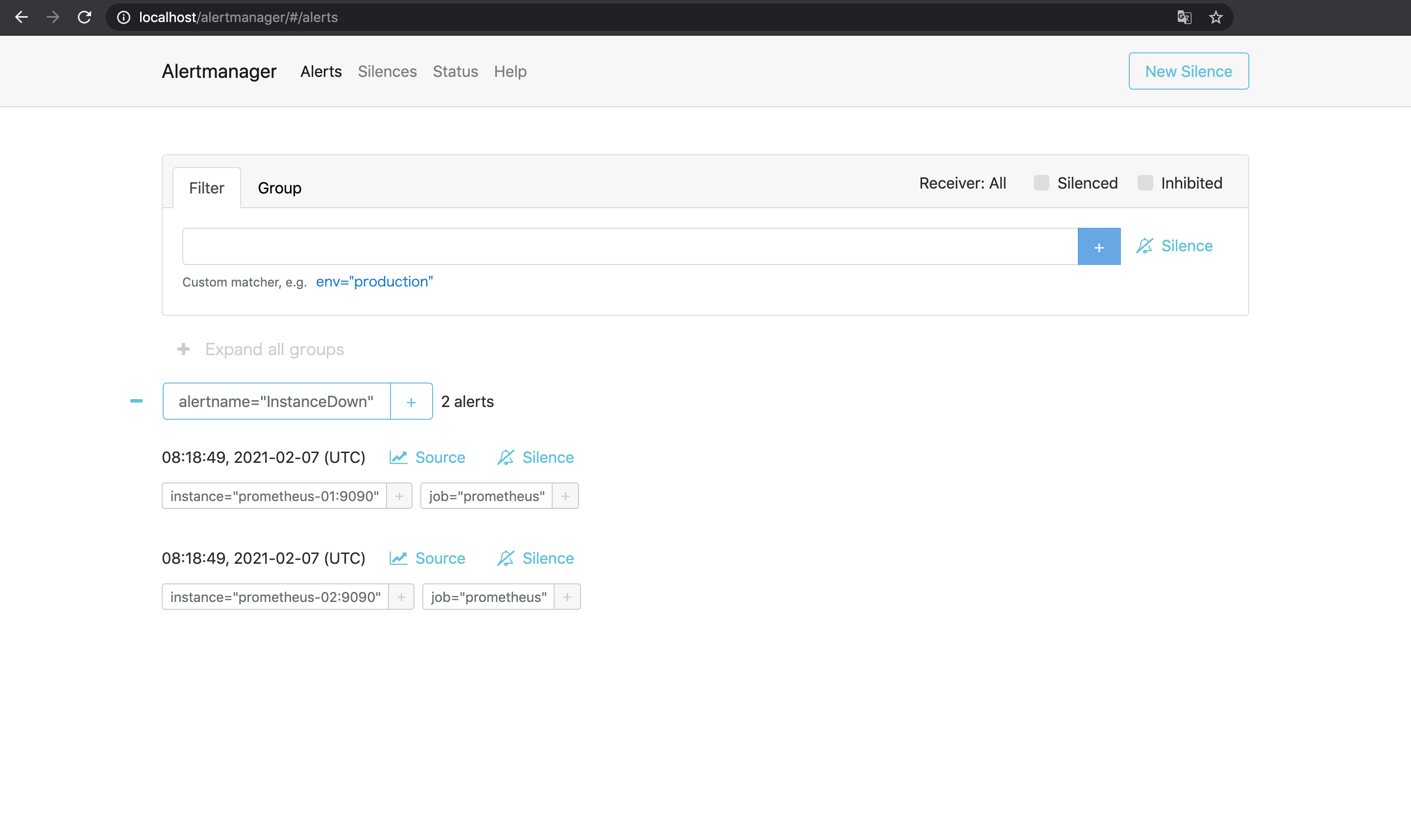
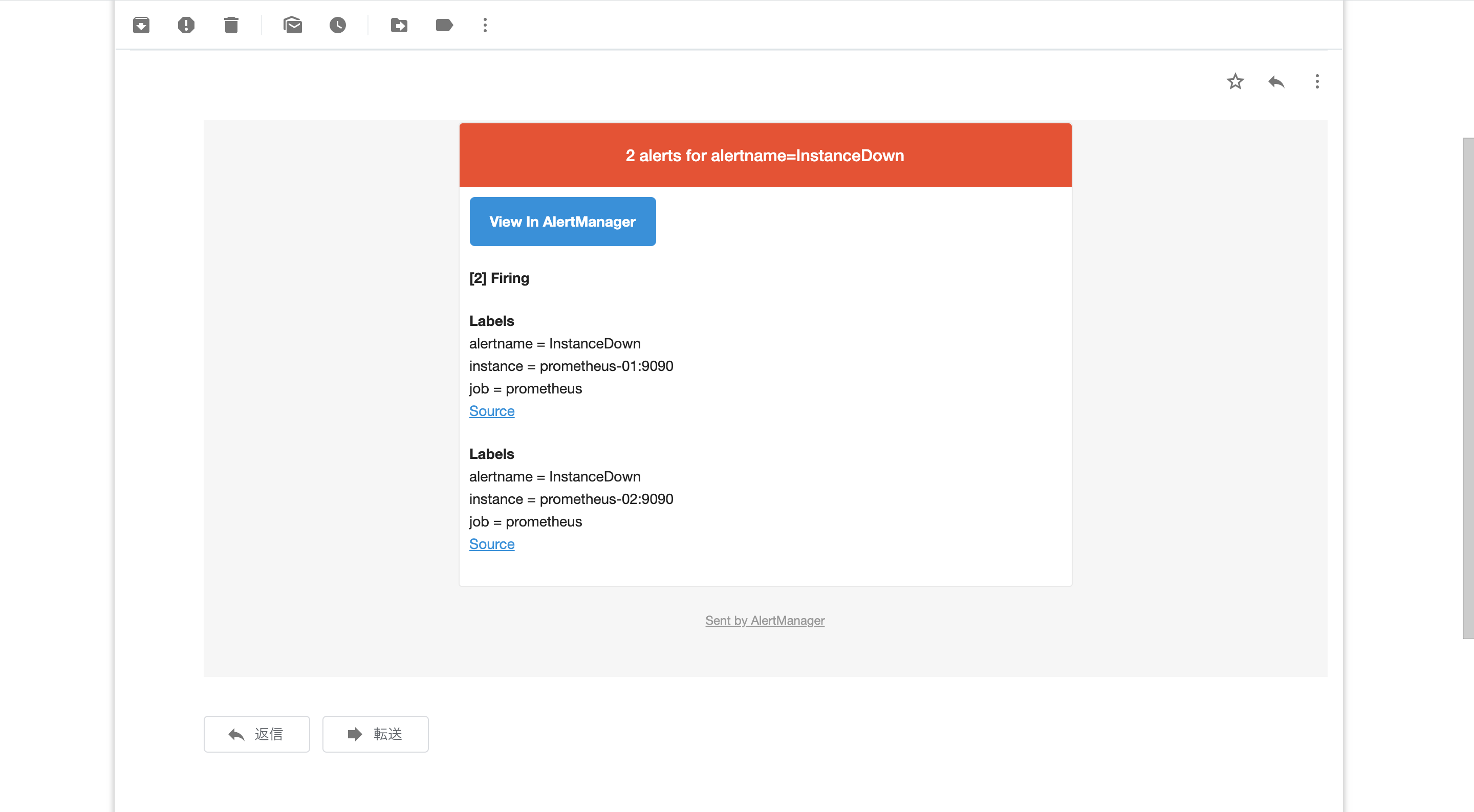
Alertmanagerが反応し, アラートの通知が届く.
(通知はAlertmanagerからGmail経由で送る設定にしている)
冗長構成にしたおかげで複数台用意したPrometheusが一部落ちてもメトリクスは継続して収集されていることと,
相互監視の設定により一部が落ちた場合にも残りのPrometheusでアラートが発火して検知できることが確認できた.
今度はAlertmanagerで複数のPrometheusから送られた同じアラートが重複排除されることを確かめるため, 3台目のPrometheusだけを落としてみる.
# Prometheusを復旧させる
$ docker-compose start prometheus-01 prometheus-02
# 3台目だけを落とす
$ docker-compose stop prometheus-03
$ docker-compose ps
Name Command State Ports
----------------------------------------------------------------------------
alertmanager /bin/alertmanager --config ... Up 9093/tcp
grafana /run.sh Up 3000/tcp
nginx /docker-entrypoint.sh ngin ... Up 0.0.0.0:80->80/tcp
prometheus-01 /bin/prometheus --config.f ... Up 9090/tcp
prometheus-02 /bin/prometheus --config.f ... Up 9090/tcp
prometheus-03 /bin/prometheus --config.f ... Exit 0今度は3台目のPrometheusが落ちたので, 1台目と2台目のPrometheusで同じInstanceDownのアラートが発生する.
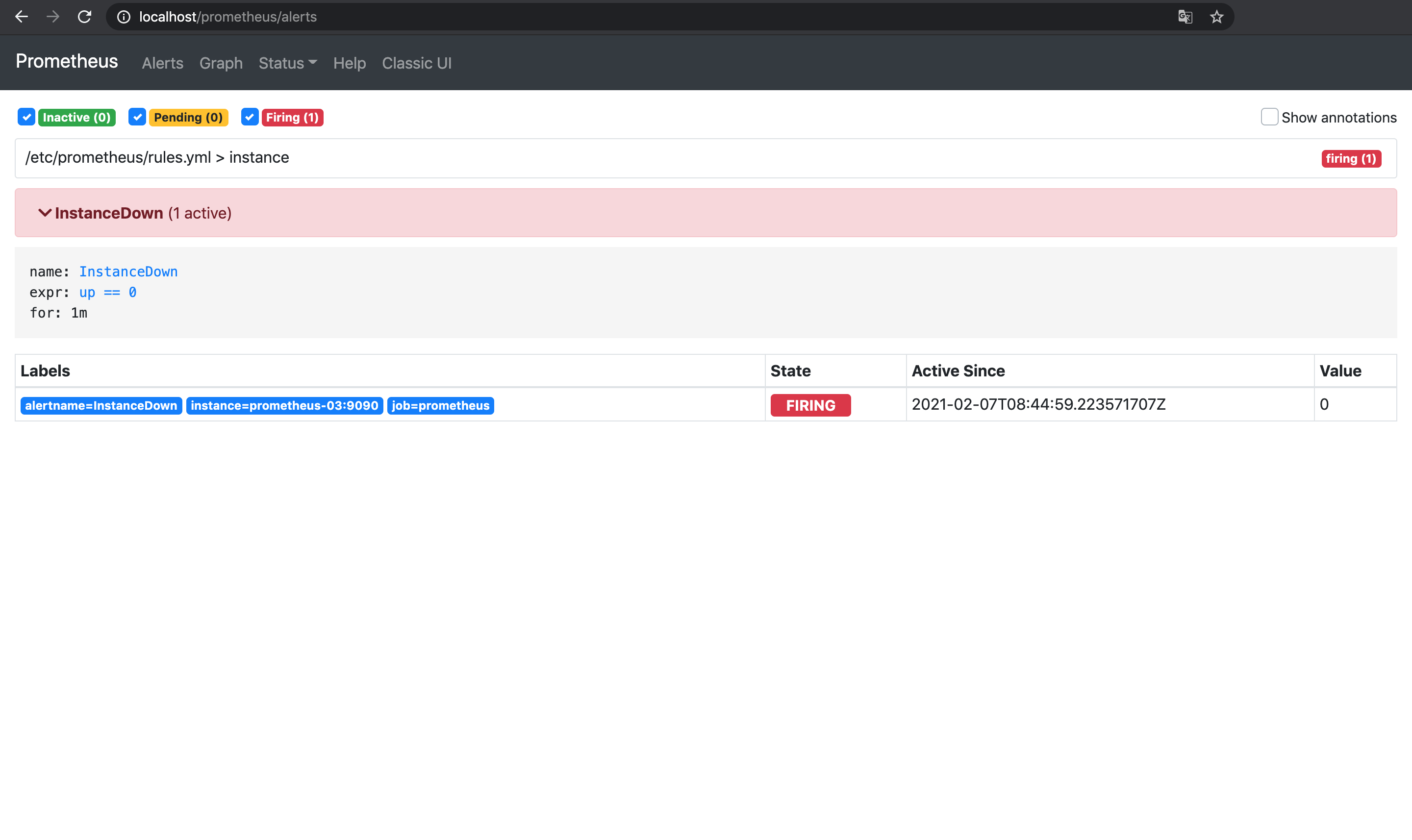
ただしAlertmanager側で重複が排除されるようになっているので, アラートは1件として扱われて通知も1件のみ届く.
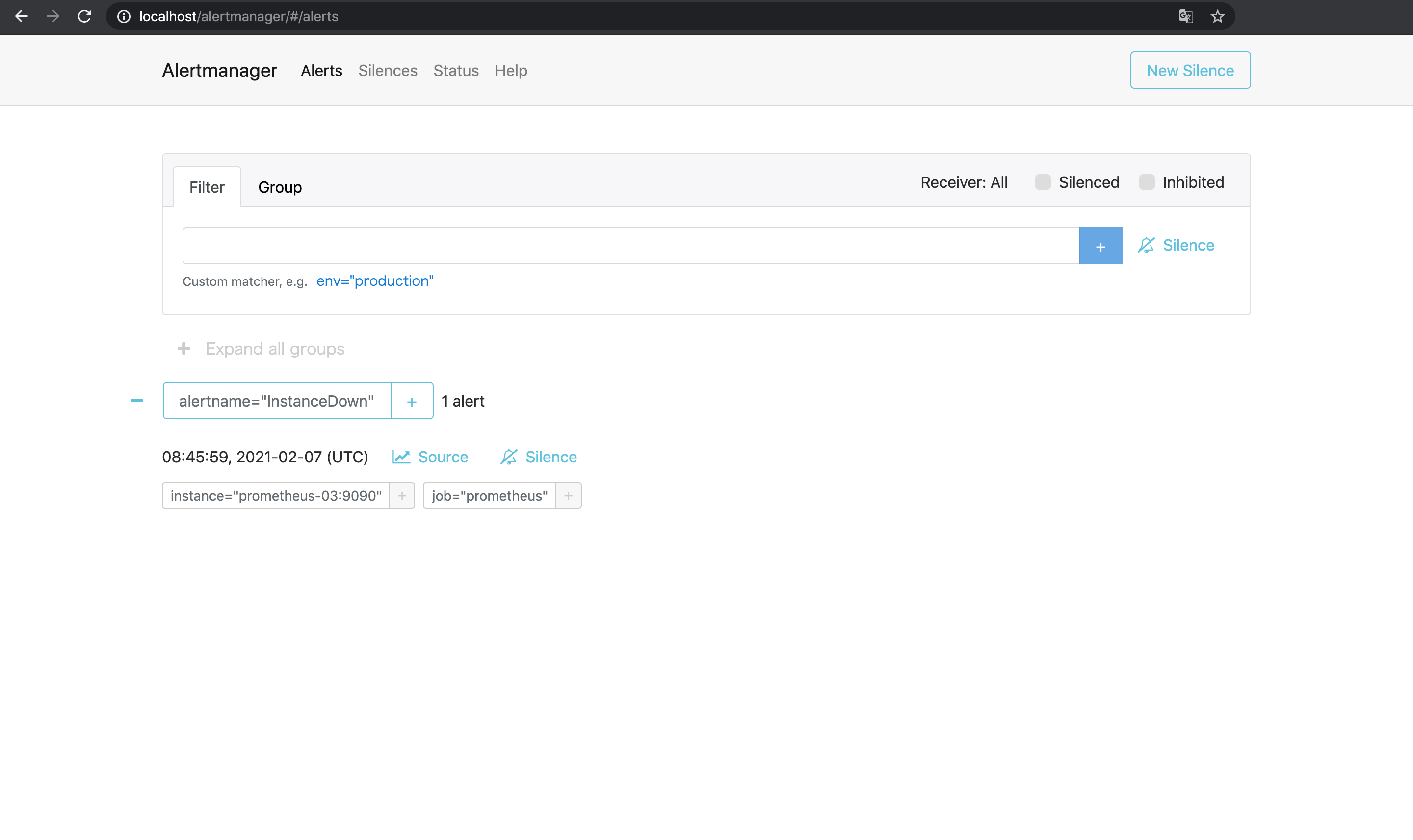
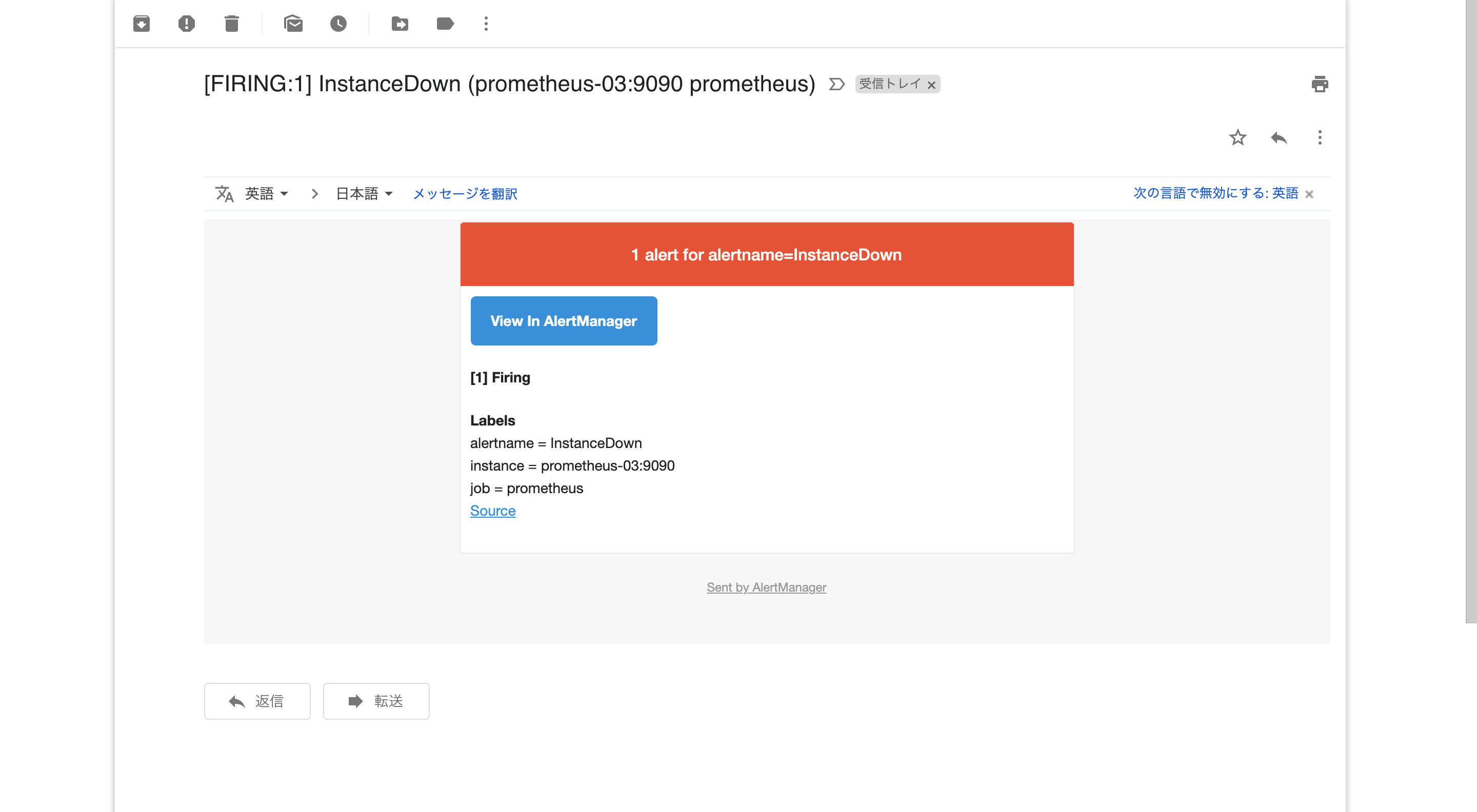
以上で複数のPrometheusで同じアラートが発火した場合でもAlertmanagerで重複排除されることが確認できた.
Alertmanagerも冗長化する
Prometheusは冗長化できたが, Alertmanagerだって絶対落ちないとは限らないのでこれも冗長化したい.
ただしAlertmanagerの場合は実際に通知を送る機能があるため, Prometheusのように単純に同じものを複数用意するのはあまり良い方法ではなさそう.
(1つのアラートに対して複数のAlertmanagerがそれぞれ通知を送ってしまう)
このため, 複数のAlertmanagerを同時に動かす場合は互いの状況を知るためにメッシュを構成する3.
難しそうに思えるがAlertmanagerの冗長化機能はあらかじめ有効化されているので, 実行時引数--cluster.peerで同時に動かす対象のホスト名を指定してやれば良い.
(相互の確認に使うポートは9093でなく9094であることに注意)
Prometheusx3prometheus.yml: 監視対象とアラートを送る対象に複数のAlertmanagerを追加する(必須)rules.yml: そのまま
Alertmanagerx3alertmanager.yml: そのまま- 実行時引数
--cluster.peerで他のAlertmanagerを指定(必須) - 動作確認用に9093番ポートを疎通可能にしておく(やらなくても良い)
Grafanagrafana.ini: そのままdatasource.yaml: そのまま
nginxdefault.conf: 複数のAlertmanagerのロードバランシング設定を追加(やらなくても良い)
prometheus.ymlでアラートの送信先を指定する際はnginxで負荷分散しているAlertmanagerのエンドポイント(/alertmanager)を指定したくなるが,
公式FAQによると「PrometheusからはすべてのAlertmanagerにアラートを送れ」とあるので今回はそれに従っている.
設定ファイルが準備できたら再度コンテナを立ち上げる.
# ディレクトリ構成
$ tree .
.
├── deployment
│ ├── alertmanager
│ │ └── alertmanager.yml
│ ├── grafana
│ │ ├── datasource.yaml
│ │ └── grafana.ini
│ ├── nginx
│ │ └── default.conf
│ └── prometheus
│ ├── prometheus.yml
│ └── rules.yml
└── docker-compose.yml
# コンテナ起動
$ docker-compose up -d --force-recreate --remove-orphans
# 今回は動作確認用にlocalhostから直接Alertmanagerにつながるようにしている
$ docker-compose ps
Name Command State Ports
---------------------------------------------------------------------------------
alertmanager-01 /bin/alertmanager --config ... Up 0.0.0.0:8093->9093/tcp
alertmanager-02 /bin/alertmanager --config ... Up 0.0.0.0:8094->9093/tcp
alertmanager-03 /bin/alertmanager --config ... Up 0.0.0.0:8095->9093/tcp
grafana /run.sh Up 3000/tcp
nginx /docker-entrypoint.sh ngin ... Up 0.0.0.0:80->80/tcp
prometheus-01 /bin/prometheus --config.f ... Up 9090/tcp
prometheus-02 /bin/prometheus --config.f ... Up 9090/tcp
prometheus-03 /bin/prometheus --config.f ... Up 9090/tcpまずはそれぞれのAlertmanagerを開いてメッシュが有効になっていることを確認する.
- alertmanager-01 : http://localhost:8093/#/status
- alertmanager-02 : http://localhost:8094/#/status
- alertmanager-03 : http://localhost:8095/#/status
Cluster Statusを見るとそれぞれのNameを互いにPeersとして認識していることがわかる.
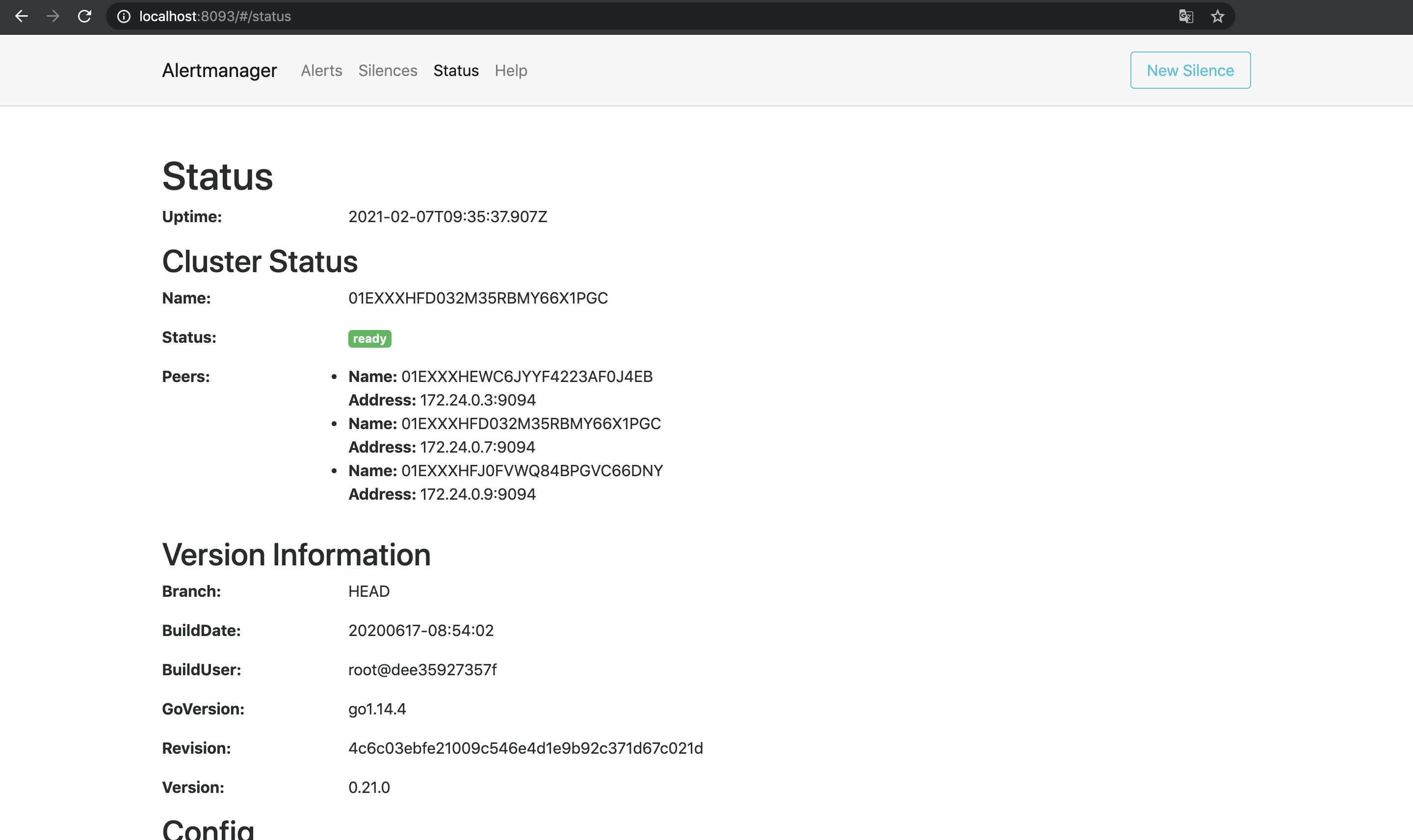
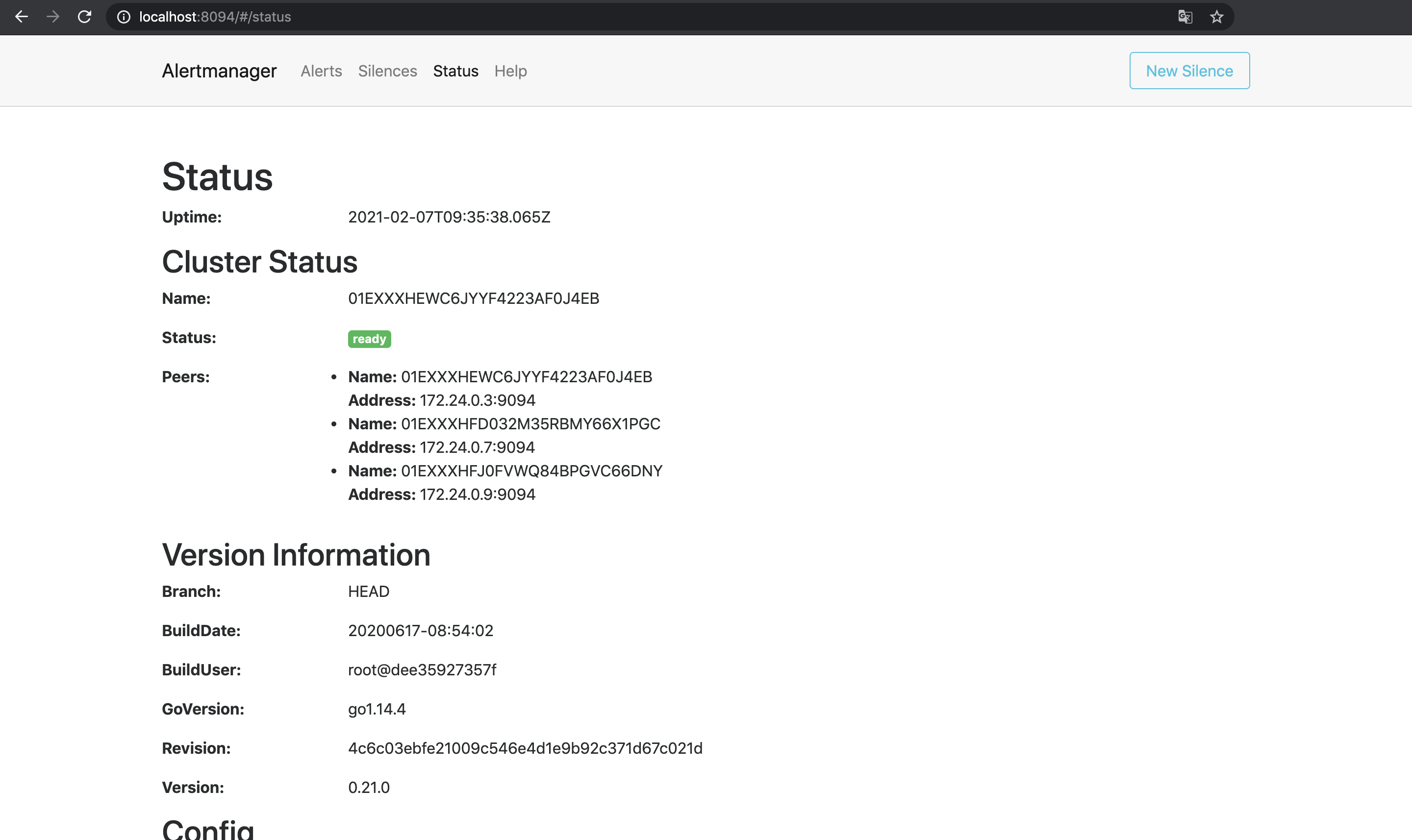
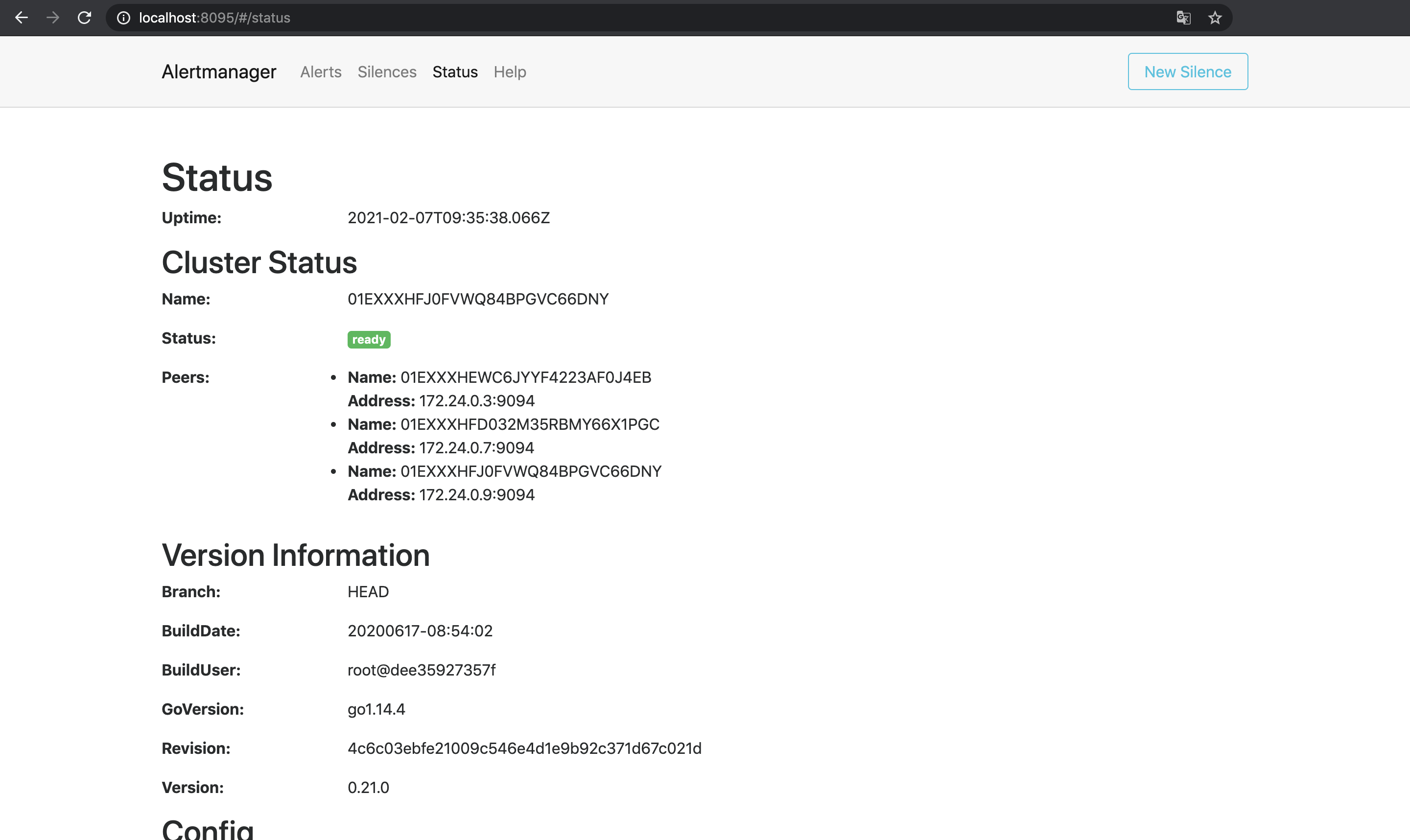
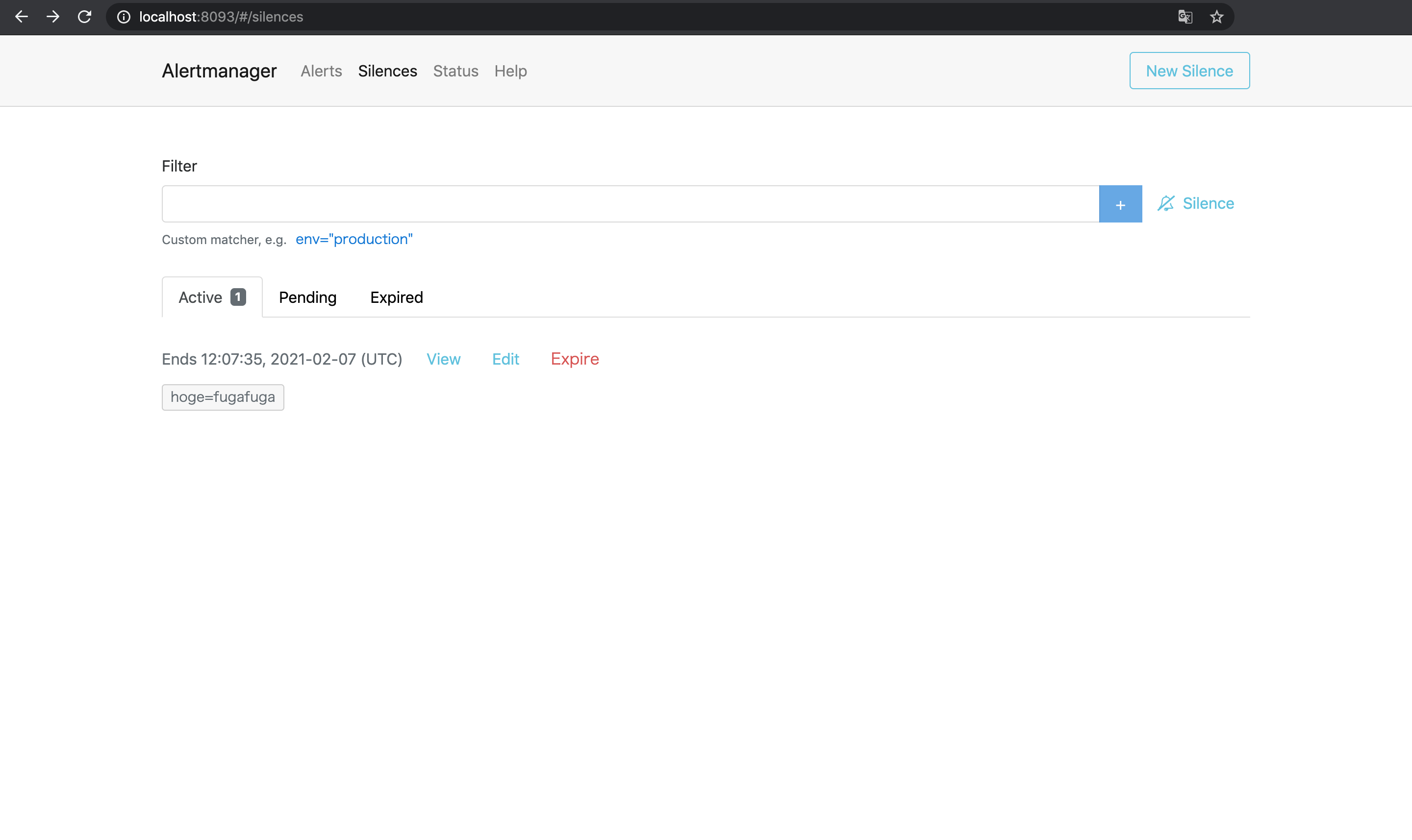
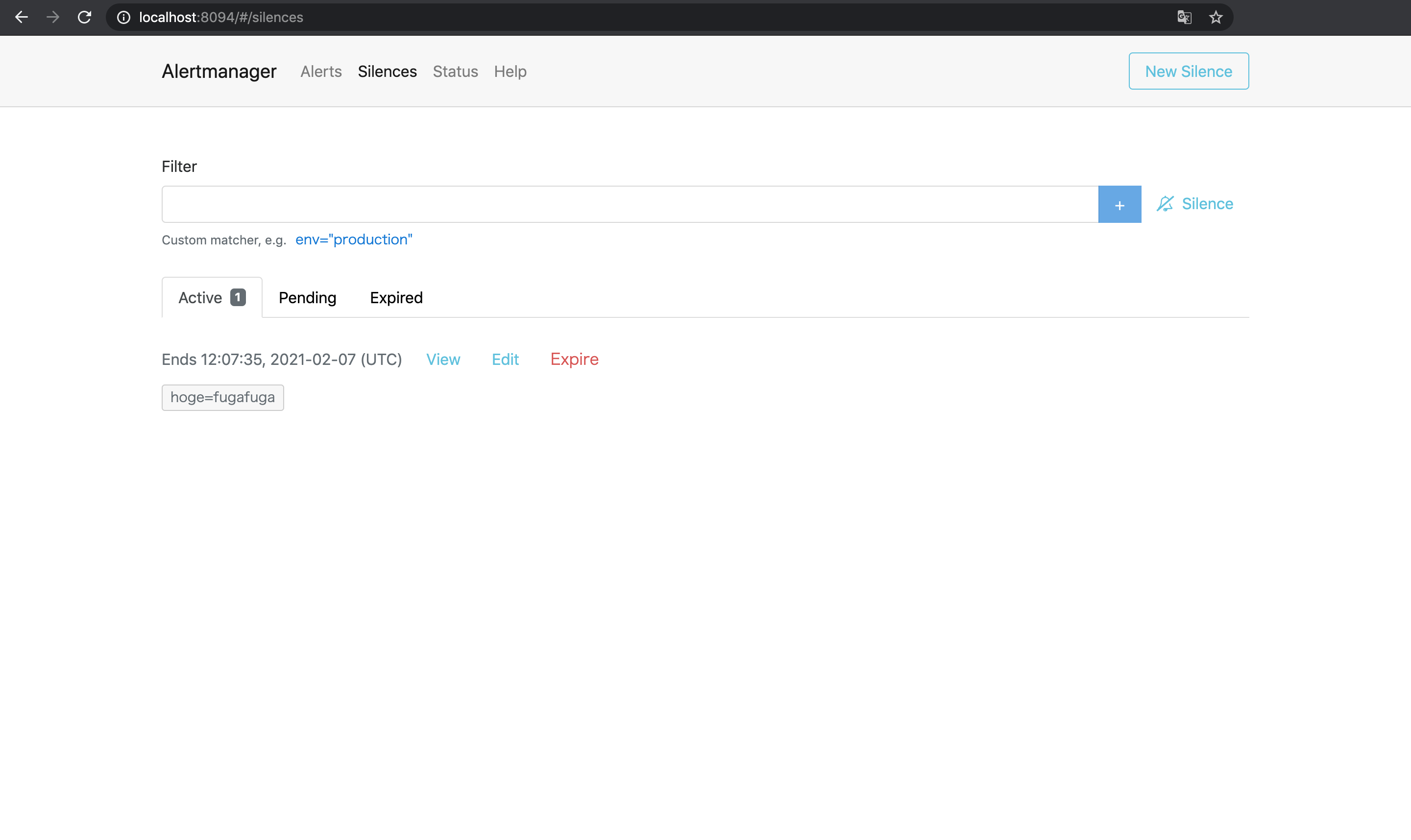
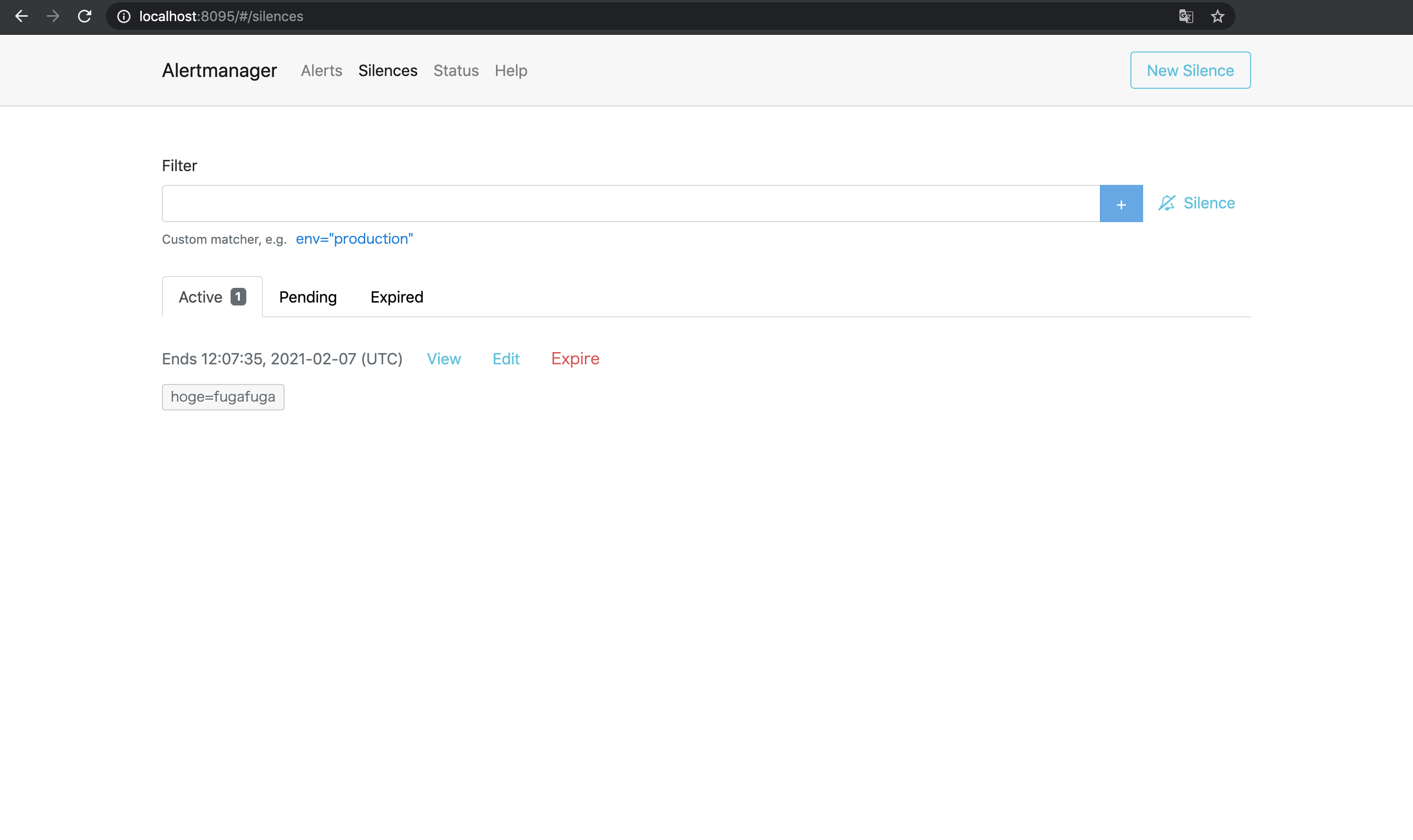
この状態で試しに1台目のAlertmanagerでSilence(アラートを一時的に無視する設定)を作成してみる4.
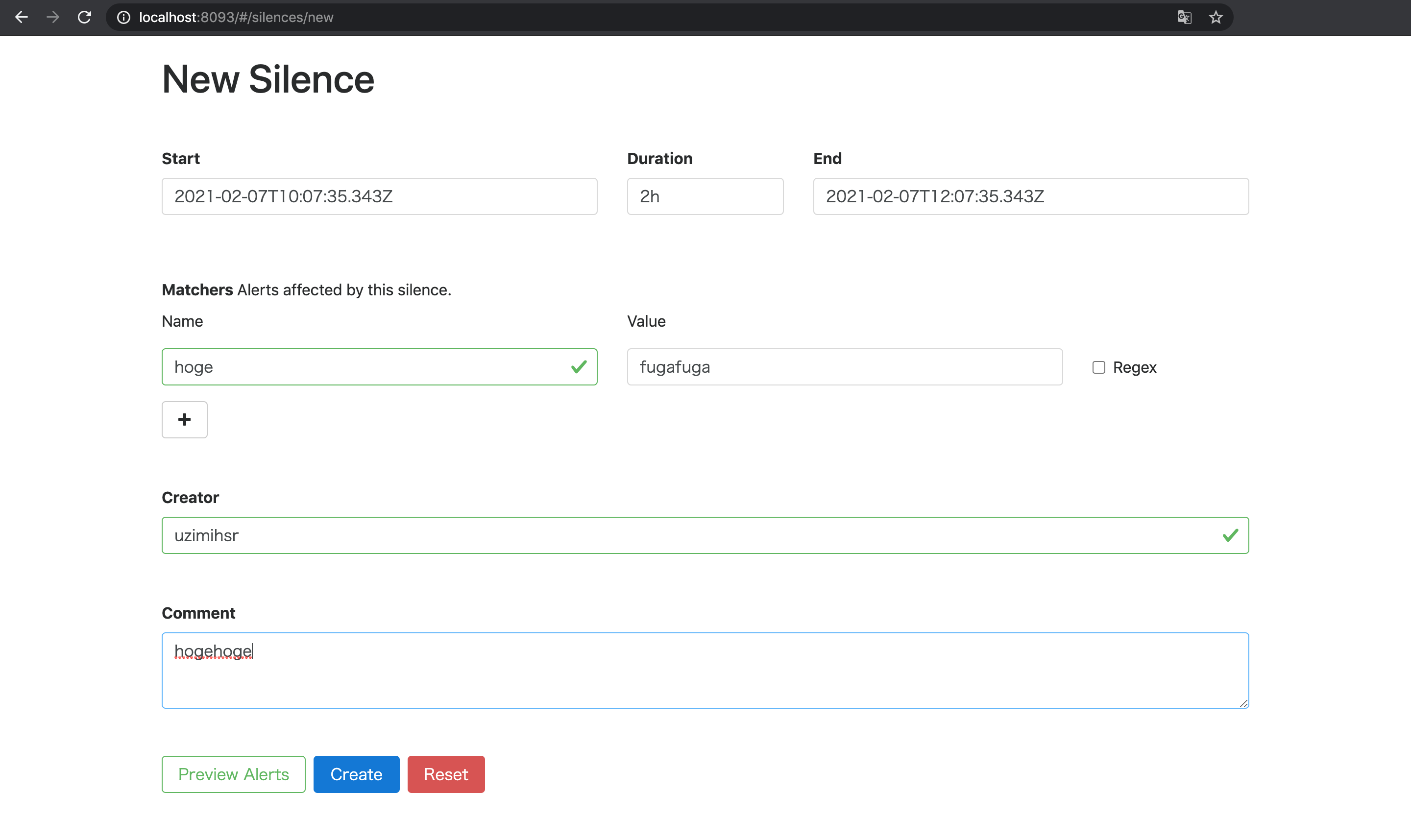
すると2台目と3台目のAlertmanagerにも同じSilenceが勝手に作成されており, これで3台のAlertmanagerがメッシュとして正しく動作していることがわかる.
最後にAlertmanagerの動作確認のため, Grafanaを落としてInstanceDownのアラートを発火させてみる.
# Grafanaを落とす
$ docker-compose stop grafana
$ docker-compose ps
Name Command State Ports
----------------------------------------------------------------------------------
alertmanager-01 /bin/alertmanager --config ... Up 0.0.0.0:8093->9093/tcp
alertmanager-02 /bin/alertmanager --config ... Up 0.0.0.0:8094->9093/tcp
alertmanager-03 /bin/alertmanager --config ... Up 0.0.0.0:8095->9093/tcp
grafana /run.sh Exit 0
nginx /docker-entrypoint.sh ngin ... Up 0.0.0.0:80->80/tcp
prometheus-01 /bin/prometheus --config.f ... Up 9090/tcp
prometheus-02 /bin/prometheus --config.f ... Up 9090/tcp
prometheus-03 /bin/prometheus --config.f ... Up 9090/tcp今までと同じくupが0になり, Prometheusでアラートが発火する.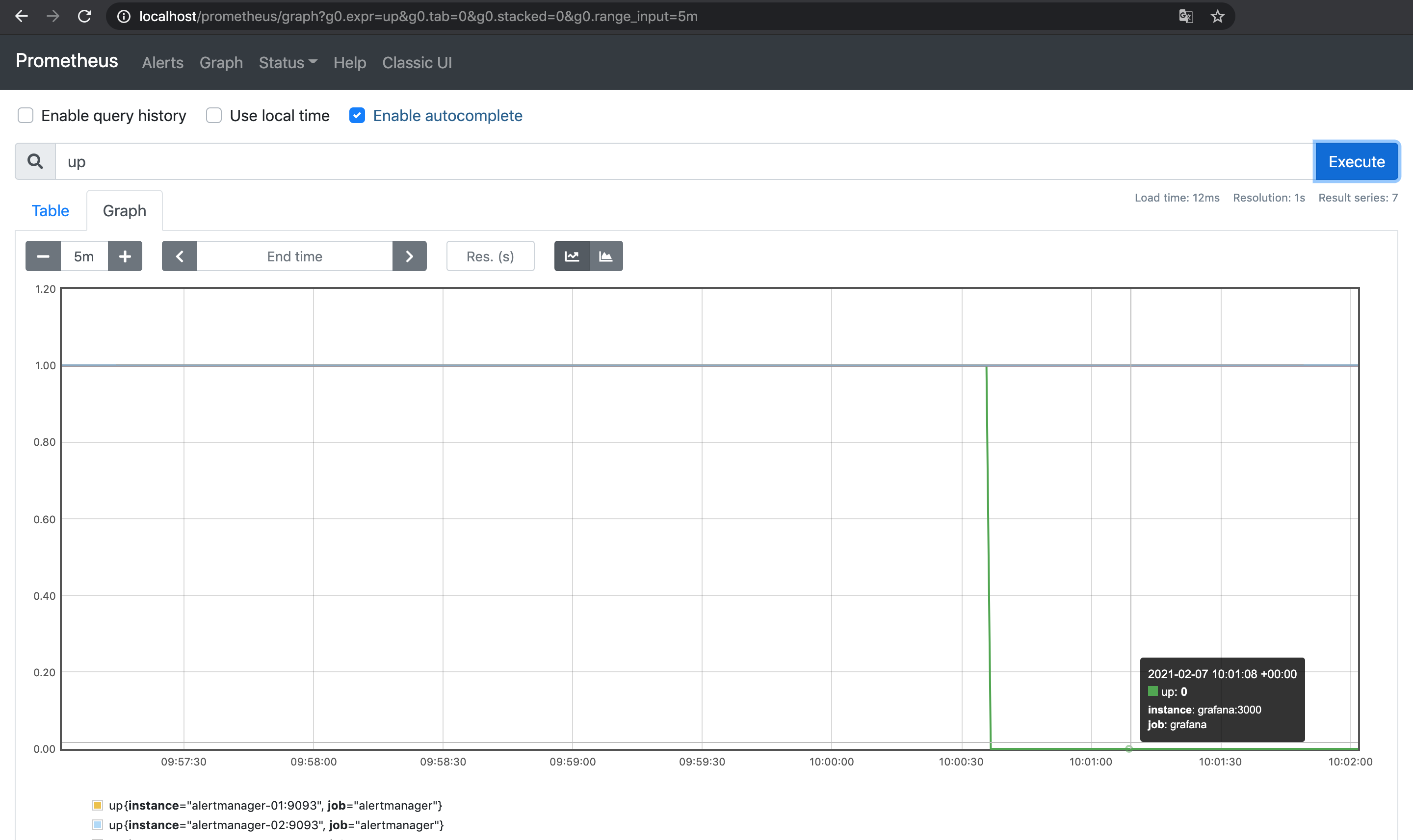
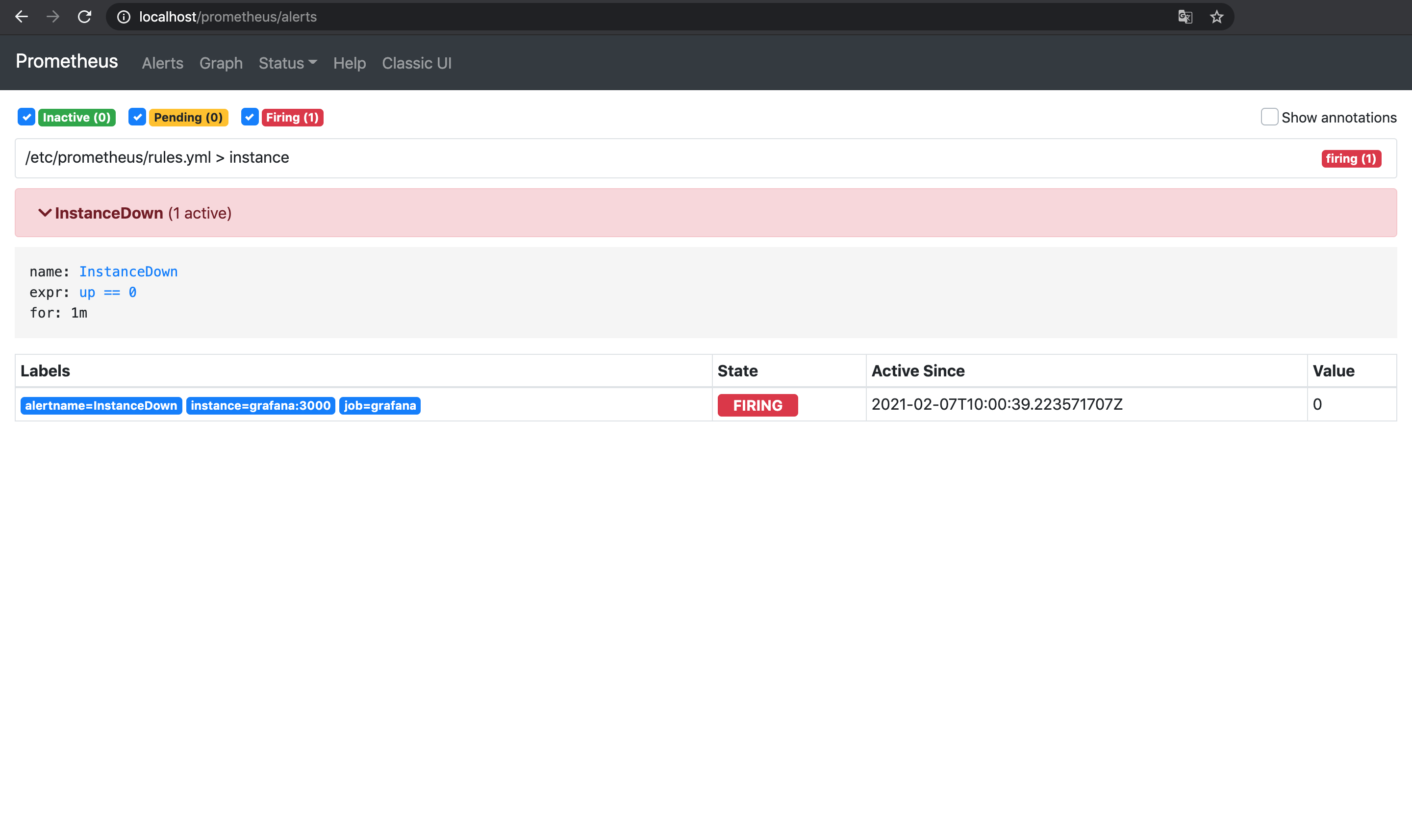
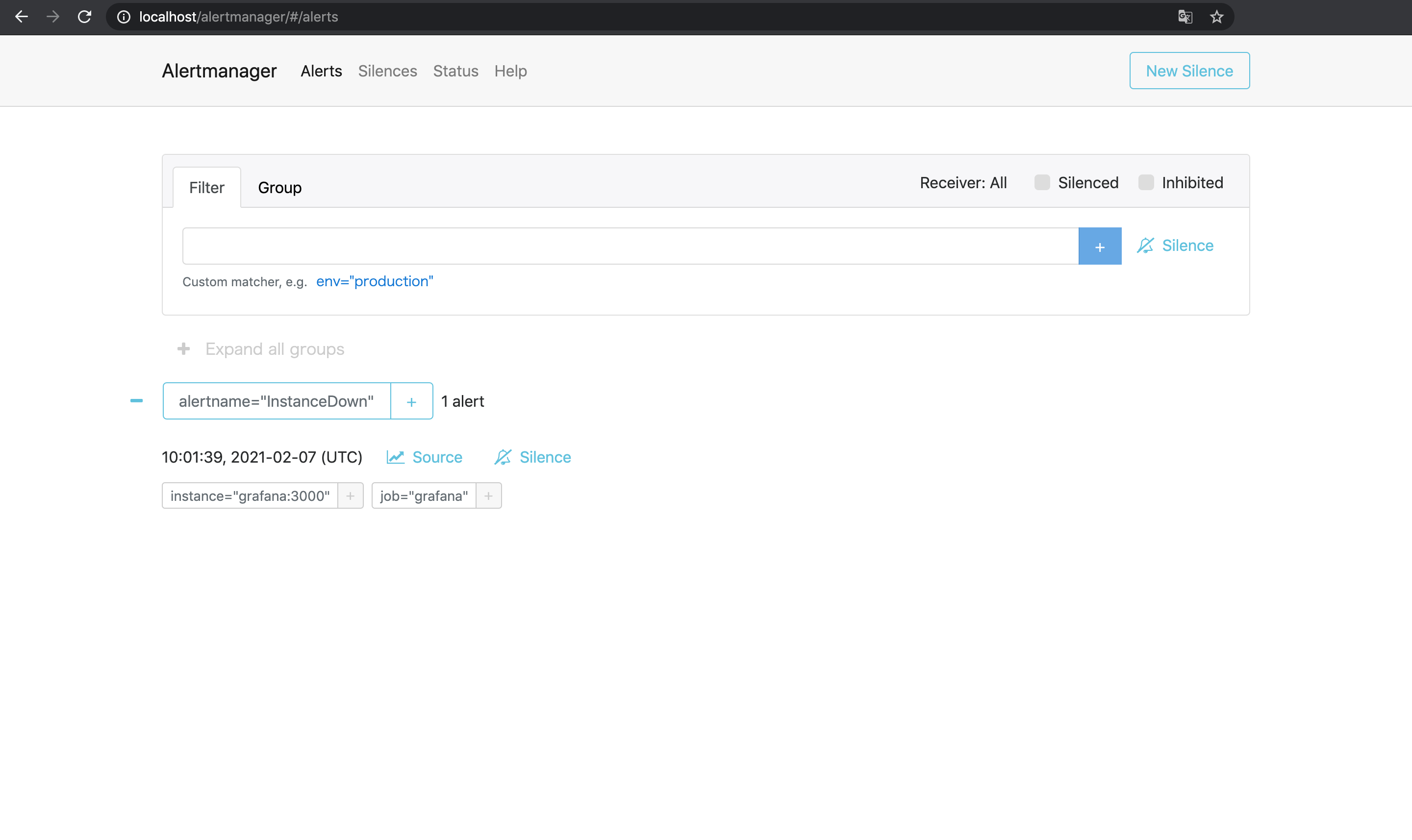
Alertmanager側でもアラートを受け取っているが,
先程確認したとおり3台のAlertmanagerはメッシュとして動作しているのでそれぞれが動作して3回通知が送られるということはなく通知は1件のみ届く.
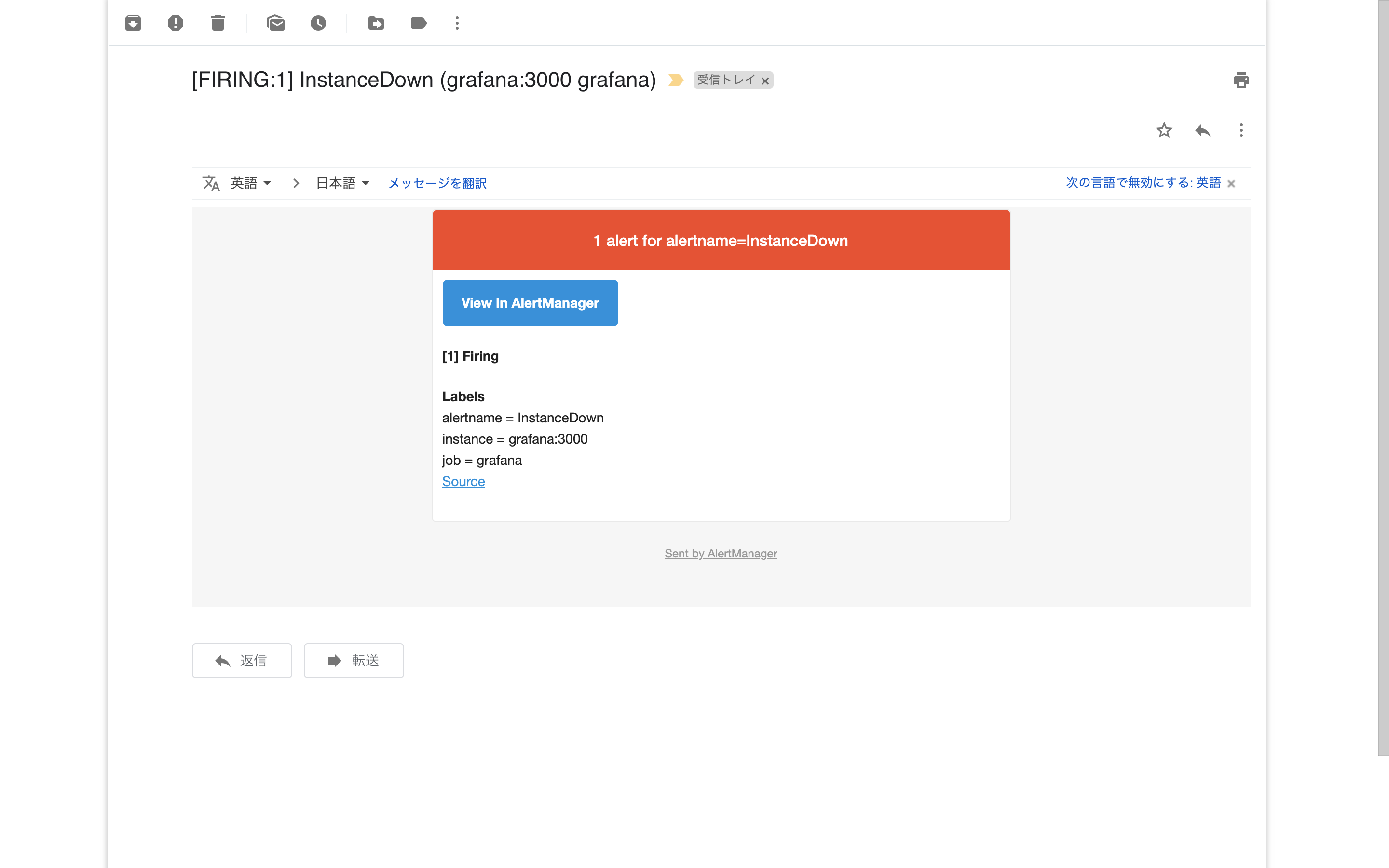
やったぜ.PrometheusだけでなくAlertmanagerも冗長構成で動かすことができた.
おわり
PrometheusとGrafanaを冗長構成で動かしてみた.
今回はGrafanaの冗長化はしなかったけど, 落ちたところでグラフが見られなくなるくらいしか困ることがないのでやらなくて正解だったかも.
(やったとしてもnginxの下に複数台ぶらさげるだけになりそう)
今回はDocker Composeで試してみたけど, 実際にそれぞれ別のサーバーで動かす場合もコンテナ名で名前解決している部分をホスト名に変えてやれば同様の動作になるはず.
お金と時間に余裕があればVMとかで試してみたい(たぶんやらない).
おまけ

https://prometheus.io/docs/introduction/faq/#can-prometheus-be-made-highly-available ↩︎
https://nginx.org/en/docs/http/ngx_http_upstream_module.html ↩︎
https://github.com/prometheus/alertmanager#high-availability ↩︎
https://www.robustperception.io/high-availability-prometheus-alerting-and-notification ↩︎